
 有趣
有趣 狗狗
狗狗 猫猫
猫猫 小宠
小宠 推荐
推荐美团的龙猫开源大型模型体系,如何实现低延迟交互?
摘要: 美团的龙猫开源大型模型体系通过创新的架构设计和优化技术实现低延迟交互。其核心在于智能调度计算资源和端到端的多模态处理,让庞大模型也能快速响应。智能调度减少计算负载传统大模型容易陷入“参数越多、延迟越高 ...
美团的龙猫开源大型模型体系通过创新的架构设计和优化技术实现低延迟交互。其核心在于智能调度计算资源和端到端的多模态处理,让庞大模型也能快速响应。 智能调度减少计算负载传统大模型容易陷入“参数越多、延迟越高”的困境,但龙猫体系的最新成员LongCat-Flash-Omni打破了这一规律。它采用一种名为**Shortcut-Connected MoE(ScMoE)**的架构,并引入了“零计算”专家机制。 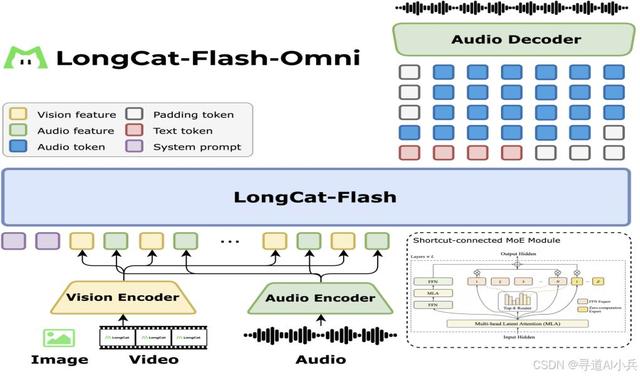 虽然模型总参数高达5600亿,但每次推理时,系统会像智能调度员一样,根据任务复杂度动态激活部分核心参数——实际参与计算的仅约270亿,不到总参数的5%。 这种设计带来了什么好处? 高效处理简单任务:对于输入中的常见词汇或标点,模型会将其分配给“零计算”专家,这个专家几乎不进行复杂运算,直接传递结果,极大节省了算力。动态资源分配:复杂任务才调用更多专家,确保算力“用在刀刃上”,从源头减少了无效计算,为低延迟打下基础。全模态直连提升响应速度要实现音视频的实时交互,光有高效架构还不够,还得优化信息处理路径。龙猫模型在这方面做了关键改进: 端到端全模态融合:模型通过视觉和音频编码器,将图像、语音等输入直接转化为统一的特征表示,跳过了传统多模态模型中繁琐的中间转换步骤。这就像把多种语言直接刻进DNA,无需查字典就能理解与生成,大幅压缩了处理时间。流式推理设计:所有模块都支持对音视频数据进行分块处理,无需等待完整输入即可开始响应,实现了“边输入边计算”的实时体验。效果如何?在基准测试中,该模型实现了**<300毫秒的实时交互延迟**,而同类开源多模态模型的延迟通常在800到1200毫秒之间。同时,它在文本、图像、视频和语音任务上保持了高性能,真正做到了低延迟不牺牲能力。 这些技术创新共同确保了龙猫模型在复杂交互中依然流畅自然。 |













